
TL;DR
Confluent's Tableflow and Snowflake's Datastreams signal something much bigger than new product launches: the industry has finally converged on a single goal. Operational and analytical data are becoming one continuous dataset.
The problem is that today's dominant approaches still rely on moving and copying data before it can be used. Even the most advanced real-time architectures continue to pay a "Replication Tax" in the form of storage costs, latency, operational complexity, and consistency challenges.
Tableflow and Datastreams are the most sophisticated examples of this approach yet, but they remain ahead-of-time architectures built around replication and synchronisation.
This article presents a different approach: query-time architectures that, instead of creating and maintaining analytical copies of data, resolve the required data view only when it is requested. This removes the need for most replication, reduces complexity, and provides immediate access to both real-time and historical data.
The future of data infrastructure won't be defined by faster copies. It will be defined by architectures that make copies unnecessary.
The data giants just doubled down on yesterday’s architecture
Confluent and Snowflake are two of the world’s largest data focused companies that have, until now, operated in their own specialist arenas.
Confluent is one of the defining infrastructure companies of the data streaming era. Built by the creators of Apache Kafka, it grew into a multi-billion dollar public company by helping thousands of organisations adopt real-time data architectures and now sits at the centre of the global event streaming ecosystem.
Snowflake transformed cloud analytics, becoming one of the fastest-growing software companies in history and redefining how analytical data is stored and queried at scale. Today it remains one of the most influential companies in analytics, shaping how organisations store, process, and consume data at massive scale.
Now both companies have released projects that attempt to unify real-time and analytical data into one continuous data set. Confluent Tableflow extends Confluent’s Kafka offering to include analytical storage as Apache Iceberg and similarly Snowflake Datastreams adds support for the Kafka API to Snowflake’s platform, expanding Snowflake into real-time workloads.
These are not random product launches, they are the reflection of a movement towards open and available data in modern stacks and they all lead to the same inevitable conclusion:
The distinction between operational and analytical data is gone. In its place is one continuous, fully accessible dataset stretching from now back to the beginning of time.
The industry finally agrees on the goal
Operational and analytical data have traditionally been separated. When you open your banking app and check your balance, place an order on Amazon, or update your profile on LinkedIn, you're interacting with operational data systems designed to process individual transactions with low latency and high reliability.
Analytical applications are different and question-focused. How many customers purchased in the last 30 days? Which products generated the most revenue by region? What was the average response time across all users yesterday? These workloads scan, aggregate and analyse large volumes of data rather than serving individual transactions.
As data ages its function changes from operational to analytical and the technical elements around its storage and retrieval patterns must change too. Historically we had one path:
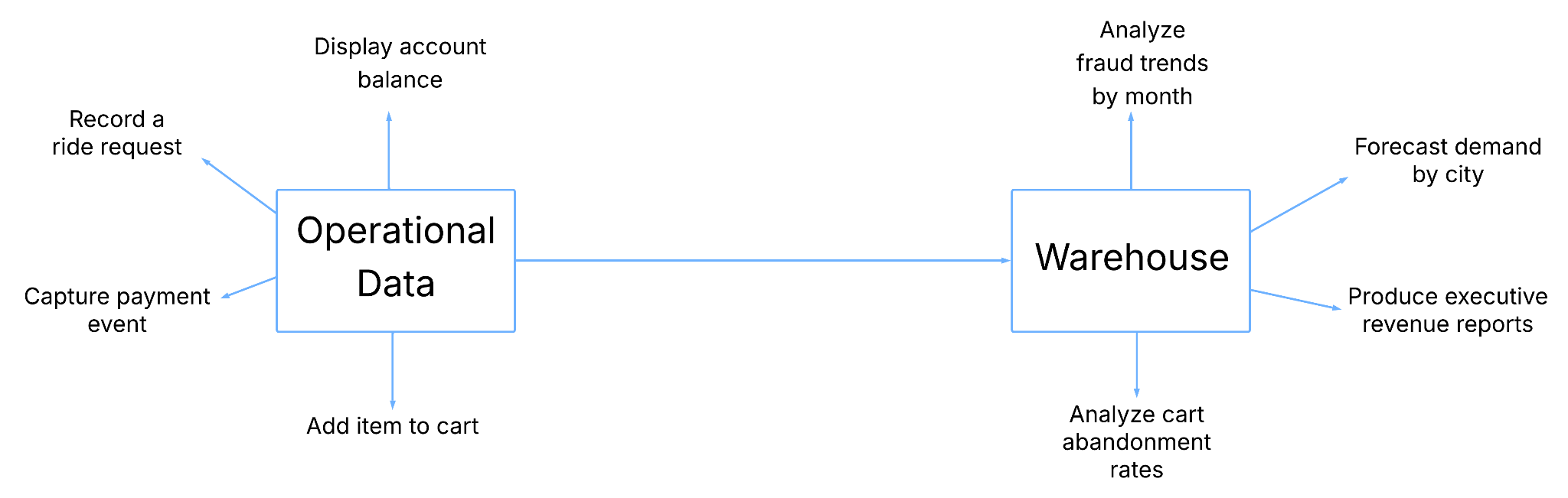
It was simple but data availability was minimal, duplication was high and delays were long.
More recently data streaming added new opportunities:
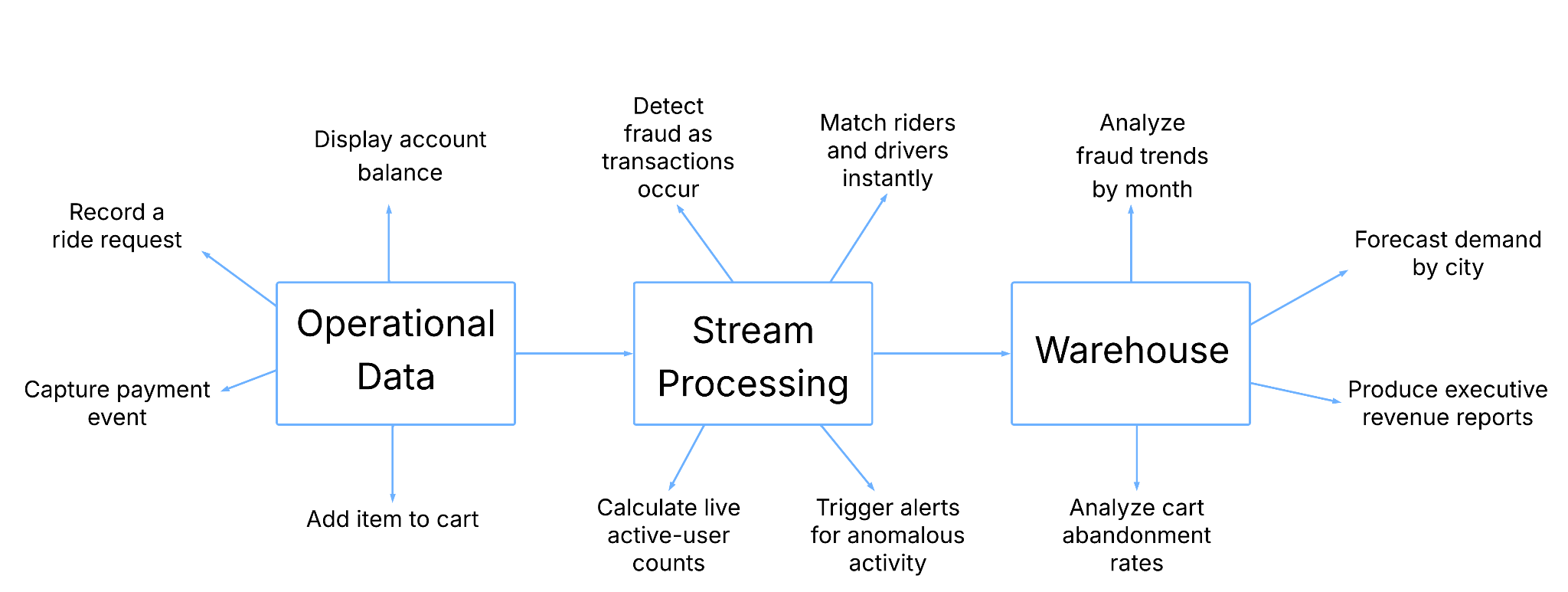
This created additional paths with improved freshness and flexibility at the cost of a growing web of pipelines, destinations, and operational complexity.
This complexity is beginning to bite in terms of cost and maintenance and the reaction to this created a new set of goals around data serving:
Complete data availability — every application should be able to access the data it needs, regardless of where or when it was created.
Low-latency access at any scale — systems should support both transactional and analytical workloads without forcing users to choose between freshness and volume.
Minimal data movement — data movement adds latency and complexity and should be the exception, not the default.
Simple access semantics — developers should not need different programming models, APIs, or storage abstractions for every use case.
Operational simplicity — fewer pipelines, fewer destinations, and fewer systems to manage.
No widely adopted approach satisfies all of these requirements and the industry standard: ETL/ELT is the farthest away of them all.
The last twenty years have been one long attempt to make ETL less painful
The early days of data architecture revolved around large overnight batches. Operational systems captured transactions throughout the day, and ETL pipelines copied those transactions into data warehouses for reporting and analysis. The approach worked, but analytics was always behind and far less effective than promised. Initially it was believed the problem was with the volume of data collected, the solution to this: “Big Data” meant that every available data point was stored for later examination (or more likely never seen again).
In reality, the issue was in data velocity not volume. As demand for fresher data increased, the industry evolved. Batch became streaming, Kafka became the backbone of real-time data movement and patterns like Change Data Capture (CDC) emerged to offer immediate response to new events in the system. Data could now be copied continuously rather than once per day.
The results were immediate and impressive. Latency dropped from hours to minutes, and eventually from minutes to seconds. Streaming systems became more and more sophisticated and more specialized to the use cases they address. Simple data movement evolved into a complex ecosystem of stream-table joins, stateful processing engines, materialised views, lakehouse integrations, and streaming warehouses all designed to make data available in the right form before it was needed.
Many of these architectures are considerable engineering feats, but the underlying principle remains unchanged: data must still be copied from one place to another before it becomes available. This is known as ahead-of-time architecture, where access to data depends on a sequence of earlier movement and transformation steps.
Ahead-of-time architectures are by nature, copy heavy. Every copy introduces costs related to transfer, transformation, storage, monitoring and governance. Collectively, these costs form what we call the Replication Tax: the latency, infrastructure, operational complexity, and loss of agility that arise whenever data must be copied before it can be used.
Why are we still paying the Replication Tax?
At the heart of every ahead-of-time architecture lies the Replication Tax. The moment data must be copied before it can be used, the following is incurred:
- Storage tax – The moment data is copied into a warehouse, lake or intermediate filesystem, there are now multiple physical representations of the same information. In most organisations with mature real-time capabilities, there are in fact multiple copies (intermediate tables, materialised views, aggregates and derived datasets). “Storage is cheap, runs the old adage, but at scale it is never free.
- Freshness – A replicated dataset can only ever be as current as its last synchronisation. Modern streaming systems have reduced this delay dramatically, but they have not removed it. Whether the lag is measured in hours, seconds or milliseconds, there is always a period during which the source system and the analytical representation disagree. What’s more, most attempts to reduce this lag involve an awkward compromise between reduced lag and efficient storage with a single system optimised for both impractical.
- Operational complexity – Replication means pipelines. Pipelines mean monitoring, retries, evolution, backfill, failure recovery and ownership. Entire categories of infrastructure exist solely to support the movement of data from one place to another.
- Consistency – Once multiple copies of data exist, what happens when they differ? Organisations must continuously answer difficult questions. Which is the source of truth? Why do two reports show different numbers? Has the latest update propagated yet? What caused the discrepancy: lag, transformation logic or a failed pipeline? Every additional copy creates another opportunity for reality to diverge.
Individually, these costs appear manageable. Collectively, they consume the enormous amount of engineering effort, infrastructure spend, and organisational attention that have become synonymous with the modern data stack.
What’s remarkable is that most discussions about real-time analytics focus on reducing the Replication Tax rather than questioning whether it should exist at all. The industry has become extraordinarily good at moving data and much less good at questioning whether the data needed to move in the first place.
Tableflow and Datastream are the peak of ahead-of-time architectures
It's important to be clear about what we're not arguing. Tableflow and Datastreams are not bad products. In fact they are quite the opposite. Both represent huge engineering achievements from two of the most successful and talent-laden data infrastructure companies in the world. They are the result of years of investment, deep expertise and a genuine understanding of real-world data problems. These products reduce latency, automate data movement and simplify integration. They make replicated analytical datasets more accessible, more consistent and more real-time than ever before.
But when the most sophisticated implementations of an architectural pattern still suffer from the same fundamental limitations as their predecessors, it is worth asking whether the problem lies in the implementation or the pattern itself?
Tableflow and Datastream do not eliminate replication. They only make replication faster.
They do not eliminate synchronisation. They only automate synchronisation.
They do not eliminate copies of data. They only create and maintain those copies more efficiently than ever before.
The question is no longer whether ahead-of-time architectures can be improved, it’s whether ahead-of-time architectures are still the right abstraction for today’s data requirements.
The hidden assumption nobody questions
The assumption made by ETL up until now is easily expressed and simple:
Data must be present in its analytical format before it can be queried for analytics and present in its operational format before it can be accessed by operational applications.
On the face of it it makes so much sense that few have asked a very basic question.
Why?
We’ve spent decades optimising the answer but very few have questioned the assumption.
Query-time architectures
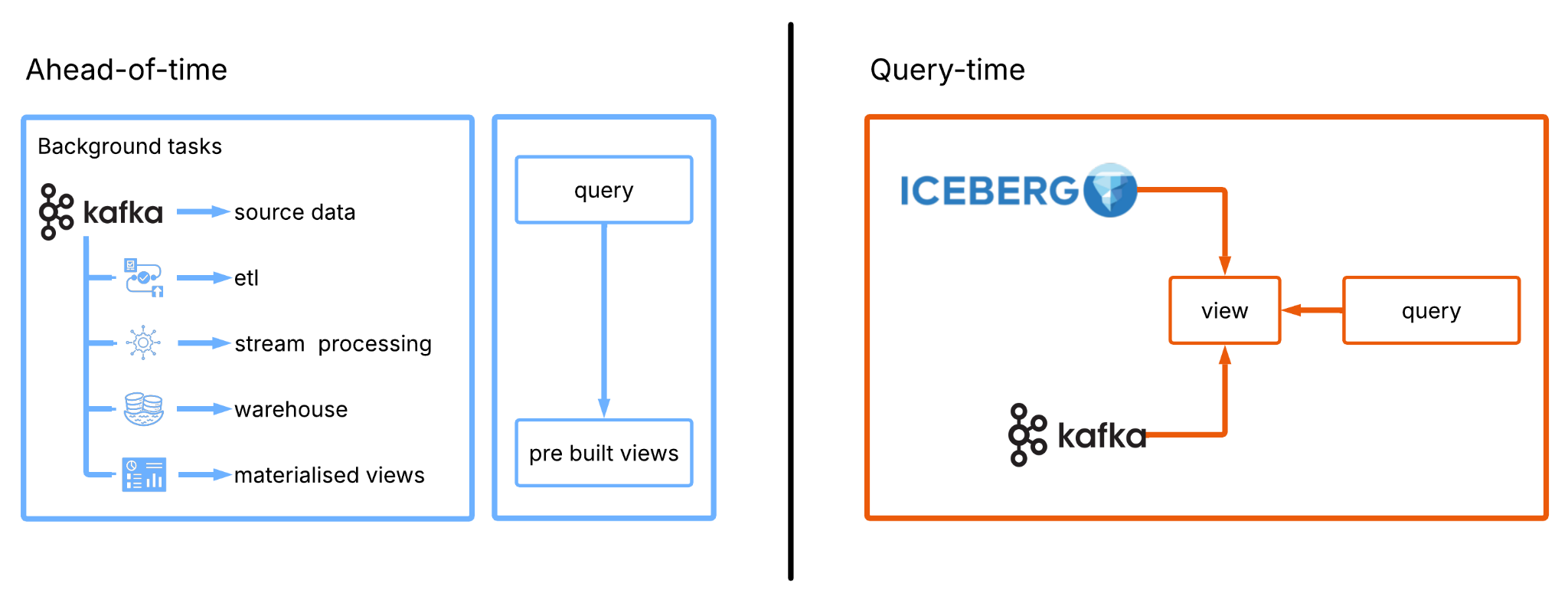
The alternative to ahead-of-time architectures are query-time architectures. As the name suggests, instead of continuously transforming and materialising data ahead of time, query-time architectures resolve the required representation of the data only when necessary.
It is similar in concept to a database view. When you query the view, the database system resolves the data required from any number of underlying tables and presents it only as the result of a query against it.
The distinction may seem subtle, but it fundamentally changes the architecture.
Ahead-of-time architectures require a physical representation of the data before the query (and any number of background processes to make this happen). Query-time architectures perform that work when the query arrives and only on data relevant to the query. The view exists continuously. The physical representation does not.
This eliminates the need to maintain a separate analytical copy of every dataset. There is no synchronisation process because there is nothing to synchronise. There is no analytical lag because there is no replicated analytical representation waiting to catch up.
Query-time architectures don’t pay tax
The most interesting property of query-time architectures is not that they make queries faster or systems simpler (even though they do), it's that they eliminate the need for replication. Note the word ‘need’ here: replication can still happen but is not required in order for queries to run.
Once replication disappears, the Replication Tax disappears with it:
- Storage – Ahead-of-time architectures result in bloated storage across multiple data copies. Query-time architectures start from a different premise. The source data exists as a single copy in its original form. Rather than creating another copy, the system resolves a view over it when it is requested. This ensures optimal storage layout and minimal bloat.
- Freshness – In a replicated architecture, freshness is determined by synchronisation. In a query-time architecture, there is no copy waiting to catch up. Queries resolve against the latest available source data, eliminating an entire category of synchronisation concerns.
- Operational complexity – Away go the pipelines, backfills and evolution over multiple systems. Instead there is one data copy available in multiple formats for maximum flexibility. Query-time architectures do not completely eliminate operational complexity, but they do remove the portion associated with synchronisation and that is usually the largest chunk.
- Consistency – With no copies, the question of multiple sources of truth disappears completely. The view is resolved directly from underlying data sources rather than from a chain of replicated intermediaries ensuring total consistency no matter how it is consumed.
What happens next
Architectural transitions rarely happen because engineers discover a better idea, they happen because businesses discover a cheaper, faster or more valuable way to solve a problem.
Organisations want operational and analytical workloads to converge, yet they don't want to operate increasingly complex and expensive infrastructure to make this happen.
Confluent and Snowflake offer an opportunity to delegate this complexity to better equipped, specialist services such as Tableflow and Datastream but query-time architectures offer the chance to sidestep it completely.
This is what can happen:
Within 6 months
Converged data applications will be a core requirement in any competitive organisation. Consider fraud detection: historically, a payment system would process a transaction while analytical systems independently identified suspicious behavior hours later. Today, organisations want analytical models operating directly within operational workflows, evaluating historical spending patterns, and real-time events together before a transaction is approved.
Operational and Analytical convergence enables this case and many, many more.
Within 12 months
Two classes of data infrastructure will emerge. Those based on ahead-of-time architectures and those based on query-time architectures.
Organisations built on ahead-of-time architectures will continue investing in increasingly sophisticated replication systems. Their data teams will be highly specialised, expensive and narrowly focused. As business requirements evolve, new pipelines, new materialised datasets and new synchronisation processes will be created. The architecture will continue to deliver value, but each new capability will add further complexity and fragility.
Organisations built on query-time architectures focus on flexibility. As business requirements evolve, they increasingly respond by defining new views rather than creating new copies. Data becomes a reusable asset that can be assembled into new products, applications and analytical experiences without requiring another round of extraction, transformation and replication.
Within 2 years
Almost all leading data organisations will have adopted query-time architectures. Zero-copy and virtualised datasets will move from niche concepts to mainstream architectural practices. ETL will be considered a legacy practice, increasingly occupying the same category as on-premise data centers: important, widespread, and no longer where the industry is heading.
Introducing Streambased
Streambased is a data serving platform that offers a query-time interface into composable views that span Apache Kafka and Apache Iceberg. That’s a bit of a mouthful so let’s break it down.
Composable views are datasets that are made up of a section of real-time data stored in Apache Kafka and a section of historical data stored in Apache Iceberg typically these sections will either be consecutive or overlap and Streambased will stitch them together so that applications can see a continuous set across both systems.
The ratio of real-time to historical data is elastic and tunable to the workload the view will serve. A primarily analytical workload may suit the majority of the view in Apache Iceberg whereas a primarily operational case may suit a majority Kafka layout.
These views are accessed with query-time semantics ensuring complete availability of all data in the set. Streambased offers 2 access patterns to this data:
- Access as Apache Iceberg: Streambased presents a read-only REST catalogue and S3 compatible storage endpoint that can be utilised by all today’s Iceberg engines
- Access as Apache Kafka: Streambased presents a Kafka proxy that clients can connect to to consume views as Kafka topics.
You can find out more about the Streambased architecture in the technical whitepaper here: https://streambased.io/resources/composable-real-time-analytical-engine
.png)
The future isn't faster copies
Operational and analytical data are converging into a single continuously available dataset. The distinction that defined the last thirty years of data architecture is disappearing, replaced by a world where applications, analytics and AI all expect access to the same information at the same time.
Traditional ahead-of-time architectures were designed for a world of separate systems, separate workloads and separate copies of data. They have served the industry remarkably well, but they are increasingly being stretched beyond the assumptions they were built upon. As organisations demand fresher data, lower operational complexity and greater flexibility, query-time architectures offer a fundamentally different path forward, one built around access rather than movement, views rather than copies, and availability rather than synchronisation.
.avif)


